
Helsedatastandarder og betydningen av terminologier

Andy Harrison
7. november 2023
Dette er den tredje av en serie på 3 artikler om standarder for helsedata:
- Egde om FHIR i 2023 – vår reise med HL7® FHIR®.
- Hjemme og borte – den internasjonale pasientoversikten og internasjonal pasienttilgang
- Helsedatastandarder, terminologi og AI-eksperimentering (denne artikkelen)
I de foregående artiklene har vi sett på bruken av HL7® FHIR® – Fast Healthcare Interoperability Resources-spesifikasjonen – som en standard for elektronisk utveksling av helseopplysninger. En annen viktig del av bildet er standardene for terminologier. Dette er kodene og navnene som brukes til å definere og klassifisere innholdet i pasientjournaler og registre. SNOMED CT har blitt nevnt i forbindelse med International Patient Summary. Koding av data er nødvendig for å gå fra en verden av uformaterte tekstnotater til strukturert informasjon, men det er et svært komplekst landskap, og denne artikkelen vil bare skrape i overflaten med et perspektiv fra en programvareutvikler og noen eksperimenter med generativ AI og terminologi.
Fordelene ifølge Direktoratet for e-helse er: “Gode helsedata kan samlast og bli delt ved bruk av kodar og termar. Dette gjer at vi kan følgje med på helsa til befolkninga og aktivitetane i helsetenesta. Dette bruker vi til å føresjå behov og fordele ressursar i framtida. Kodeverk og terminologi gjer det også mogleg å dele strukturerte helseopplysningar om kvar enkelt pasient for å gi betre behandling.” (https://www.ehelse.no/kodeverk-og-terminologi)
Ved å bruke koder i stedet for tekst til å beskrive for eksempel diagnoser, kan informasjonen lettere brukes til statistikk, helseovervåking, forskning og prioritering av helsefinansiering.
Helsedataterminologier kommer fra mange internasjonale og nasjonale kodesett. Noen av disse kan slås opp på nettstedet https://finnkode.ehelse.no/:
- ICD-10/11 – ICD-11 er den ellevte revisjonen av den International Classification of Diseases (ICD) brukes til diagnosekoder.
2. NCMP, NCSP og NCRP – Norske og nordiske kliniske prosedyrekoder.
3. PHBU – Multiaksial klassifikasjon i psykisk helsevern for barn og unge.
4. ICPC-2 – den International Classification of Primary Care (ICPC) er en klassifiseringsmetode for møter i primærhelsetjenesten og brukes av fastleger.
5. ICF-CY – International Classification of Functioning, Disability and Health Children & Youth Version.
6. NORPAT – Norske og nordiske patologikoder som brukes i patologilaboratorier, i rettspatologi, i biobankarbeid og ved innrapportering til Kreftregisteret.
Additional terminologies include:
7. LOINC (Logical Observation Identifiers Names and Codes) Kodesettet fokuserer primært på å identifisere laboratorie- og kliniske observasjoner, for eksempel målinger, tester og resultater. SNOMED CT (Systematized Nomenclature of Medicine – Clinical Terms) dekker som nevnt et bredt spekter av klinisk terminologi, inkludert sykdommer, prosedyrer, anatomi og kliniske begreper.
8. Volven, en nasjonal database som utgjør helsetjenestens felles metadatagrunnlag, inkludert koder, klassifikasjoner, termer, begrepsdefinisjoner, datadefinisjoner osv.
9. ICNP (International Classification for Nursing Practice) koder som er definert for sykepleiebruk, og som innlemmes i SNOMED CT.
10. ATC (Anatomical Therapeutic Chemical Classification System): ATC brukes i Norge til å kode og klassifisere legemidler i forbindelse med forskrivning, utlevering og refusjon.
Integrasjonstjenester og validering
Listen ovenfor er ikke engang uttømmende og kan virke ganske overveldende, men den gjenspeiler både utviklingen av standarder og kompleksiteten i kodekravene på tvers av hele spekteret av menneskers (og dyrs) helse.
I praksis er vi som systemutviklere og -integratorer ikke så opptatt av betydningen av kodeverkene, men av utvelgelsen og valideringen av kodene opp mot de kvalifiserte kodesettene. Her finnes det verktøy – terminologiservere – som kan brukes til kodekonvertering, oppslag, validering og oversettelse.
Les også «Egde om FHIR i 2023 – vår reise med HL7® FHIR®»
Hva tenker generativ AI om alt dette?
Da jeg tenkte på hvor mye arbeid som kreves for å kode helsedata raskt og nøyaktig, begynte jeg å lure på hva GenAI/store språkmodellverktøy som ChatGPT og Bard kan bidra med her. Det er velkjent at helsepersonell bruker tid på å skrive journalnotater og kode data som kunne vært brukt bedre sammen med pasientene. Jeg prøvde meg på et raskt, nysgjerrighetsdrevet eksperiment (jeg legger vekt på «raskt» og understreker at dette IKKE er et nøye spesifisert, validert eller testet eksperiment).
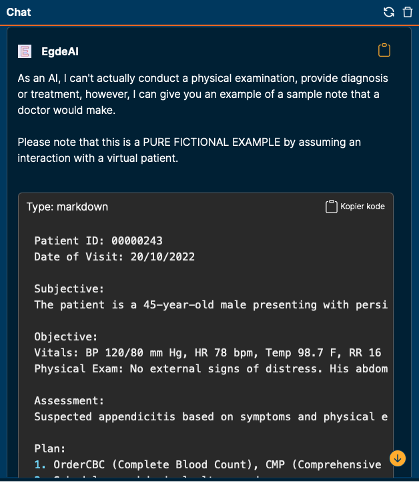 Først fant jeg ut at OpenAI ChatGPT og Google Bard hadde en form for treningsdata som dekket journalnotater (og jeg holdt meg stort sett til engelsk). Jeg la inn en innledning: «Du er en lege som skriver et journalnotat til en pasient». Dette eksemplet er Egedes tilpassede versjon av ChatGPT, som har norske svar som standard:
Først fant jeg ut at OpenAI ChatGPT og Google Bard hadde en form for treningsdata som dekket journalnotater (og jeg holdt meg stort sett til engelsk). Jeg la inn en innledning: «Du er en lege som skriver et journalnotat til en pasient». Dette eksemplet er Egedes tilpassede versjon av ChatGPT, som har norske svar som standard:
Den første forespørselen var: “Write an EHR journal note for a patient with the following symptoms: dizziness, frequent urination, and irritable bowel disease. Urine and blood tests have been ordered. Add SNOMED CT codes for all medical terms with their Norwegian translations.”

Det vi ser her, er at den kan strukturere og skrive et fiktivt notat, men at den legger til uspesifiserte detaljer i rapporten. Dette er ikke overraskende siden den skriver et notat basert på mønstrene den har sett i treningsdataene. SNOMED CT-kodene er interessante. Noen er korrekte, noen finnes, men er ikke korrekte. Andre kan ikke finnes. Bard ga lignende resultater.
For å redusere innholdet som ble skapt, men som ikke var basert på inngangsinformasjonen, kunne jeg legge til “Do not add symptoms or diagnosis not mentioned by me” til forespørselen til ChatGPT. Det fungerte ikke for Bard, men det gjorde følgende: “Do not embellish with additional information”. Jeg burde ha skjønt at det ville kreve en mer poetisk tilnærming.
GenAI og SNOMED CT-kodene
Jeg er verken overrasket eller skuffet over at mange av SNOMED CT-kodene var feil. SNOMED CT oppdateres kontinuerlig som et lisensiert kodeverk, men det har ikke noe å gjøre delvis i opplæringsdatasettet. Ethvert IT-system som etterspør koder, tekstbeskrivelser og oversettelser, bør alltid gå tilbake til kilden for referanse og validering. Jeg har siden oppdaget en måte å undertrykke SNOMED CT-kodene på og få dette mer nyttige resultatet i stedet:

I begynnelsen av juli 2023 spurte jeg Bard:

Jeg stilte det samme spørsmålet igjen i slutten av august 2023:
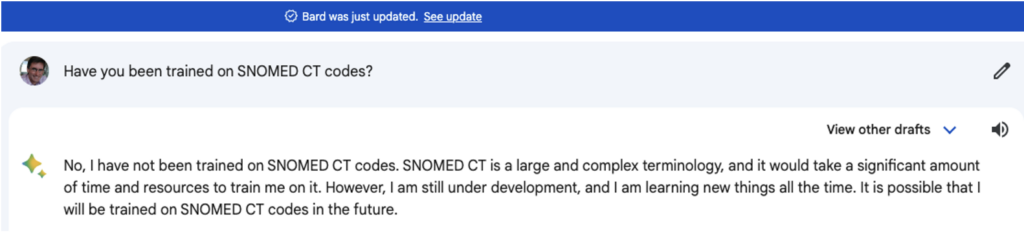
ChatGPT er noe mer forsiktig:

En sommerferie er lang tid i GenAI-verden, og denne artikkelen er sannsynlig utdatert nå.
 Finnes det et potensial her?
Finnes det et potensial her?
Disse enkle testene peker på noen ting vi bør tenke på:
1. GenAI kan lage en god struktur for denne typen formelle dokumenter (og kan trenes opp og tilpasses til å bli betydelig bedre).
2. GenAI kan legge til utfyllingstekst for å lage et lesbart dokument.
3. I et reelt system må GenAI gi brukeren valgmuligheter der det gis kritisk informasjon.
4. Kodingssystemene bør være et supplement til GenAI-utdataene, slik at brukeren kan kombinere korrekte data med de genererte dataene.
5. Vi må være smarte når vi utformer og tester slike systemer, slik at vi kan skille mellom genererte data, korrekt tolkning av inndataene og kvalifiserte formelle data som terminologier.
6. En rask studie av tilpasningsmulighetene «prompt engineering» indikerer at et slikt system ligger godt innenfor mulighetene til dagens AI-løsninger med smart programmering.